
IT/영어 공부노트
[문서읽기] 가명정보 처리 가이드라인 - 개인정보 가명처리 기술 및 예시 본문
가명정보 처리 가이드라인 - 개인정보보호위원회

개인정보 가명, 익명처리 기술 종류
| 분류 | 기술 | 세부기술 |
| 개인정보 삭제 | 삭제기술 | 삭제 Suppression |
| 부분삭제 Partial suppression | ||
| 행 항목 삭제 Record suppression | ||
| 로컬 삭제 Local suppression | ||
| 개인정보 일부 또는 전부 대체 |
삭제기술 | 마스킹 Masking |
| 통계도구 | 총계처리 Aggregation | |
| 부분총계 Micro aggregation | ||
| 일반화 기술 |
일반 라운딩 Rounding | |
| 랜덤 라운딩 Random rounding | ||
| 제어 라운딩 Controlled rounding | ||
| 상하단 코딩 Top and bottom coding | ||
| 로컬 일반화 Local generalization | ||
| 범위 방법 Data range | ||
| 문자데이터 범주화 Categorization of character data | ||
| 암호화 |
양방향 암호화 Two-way encryption | |
| 일방향 암호화-암호화적 해시함수 One-way encryption-Cryptographic hash hunction | ||
| 순서보존 암호화 Order-preserving encryption | ||
| 형태보존 암호화 Format-preserving encryption | ||
| 동형 암호화 Homomorphic encyrption | ||
| 다형성 암호화 Polymorphic encryption | ||
| 무작위화 기술 |
잡음 추가 Noise addtion | |
| 순열 Permutation | ||
| 토큰화 Tokenisation | ||
| 난수생성기 RNG | ||
가명 및 익명처리를 위한 다양한 기술 |
표본추출 Sampling | |
| 해부화 Anatomization | ||
| 재현데이터 Syntetic data | ||
| 동형비밀분산 Homomorphic secret sharing | ||
| 차분 프라이버시 Diffential privay | ||
개인정보 삭제 수치형, 문자형데이터
1. 삭제
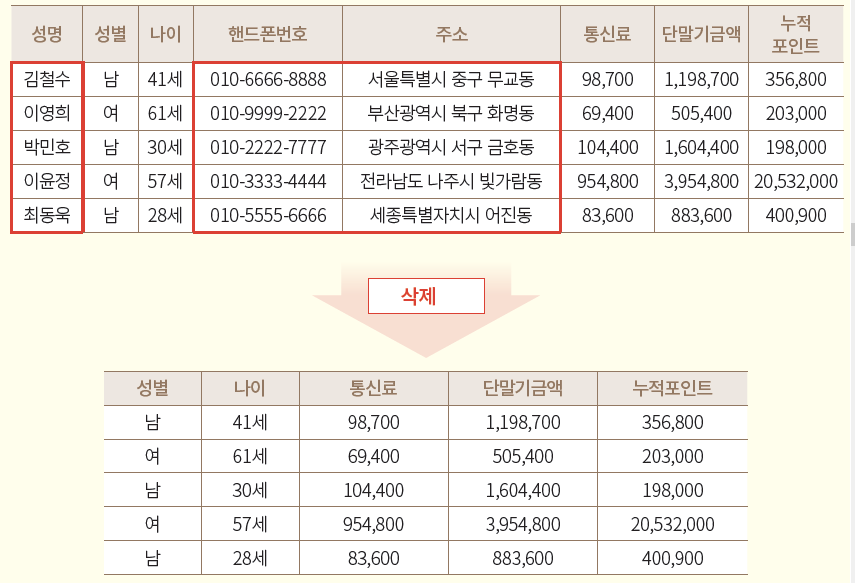
원본 정보에서 개인정보를 단순 삭제
2. 부분삭제

개인정보 전체가 아닌 일부 삭제
3. 행항목 삭제
다른 정보와 뚜렷하게 구별되는 행 항목 삭제
통계 분석에서 전체 평균에 비해 오차범위를 벗어나는 자료를 제거할 때 사용
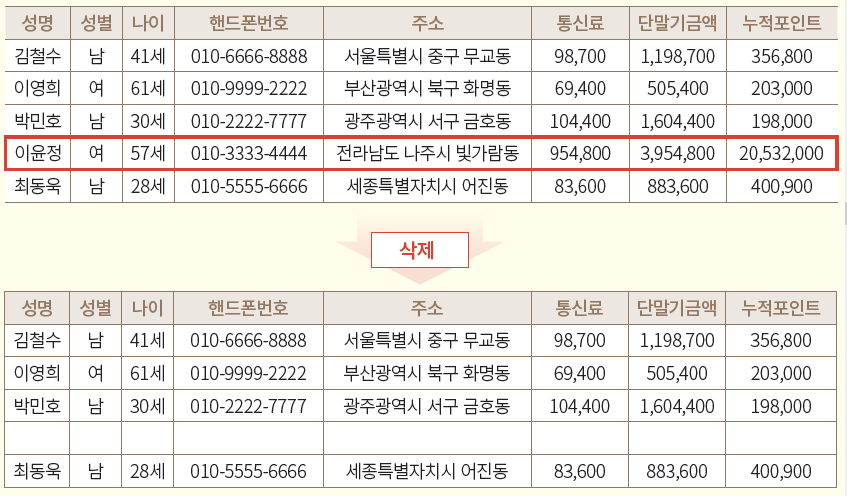
4. 로컬삭제
특이정보를 해당 행 항목에서 삭제 (위 3번 그림에서 누적포인트만 삭제하는 경우의 예시)
5. 마스킹
- 특정 항목의 일부 또는 전부를 공백이나 문자('*')로 대체
통계도구 수치형
1. 총계처리
평균값, 최댓값, 최솟값, 최빈값, 중간값 등으로 처리
데이터 전체가 유사한 특징을 가진 개인으로 구성된 경우 그 데이터의 대푯값이 특정 개인의 정보를 그대로 노출시킬 수 있으니 주의
2. 부분총계

다른 정보에 비해 오차범위가 큰 항목을 평균값 등으로 대체
동질 집한 내의 특정항목을 총계처리 하거나 특정 조건에 너무 특이한 값이 있어 개인의 식별 가능성이 높지만 분석에 꼭 필요한 값인 경우 처리
일반화기술 수치형
1. 라운딩
올림, 내림, 반올림 등의 기준을 적용하여 집계 처리
2. 랜덤라운딩
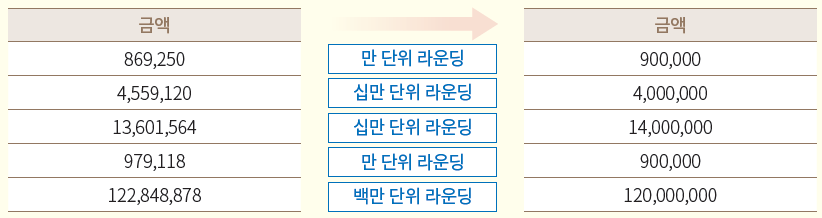
수치 데이터를 임의의 수인 자리수, 실제 수 기준으로 올림 또는 내림
3. 제어 라운딩
라운딩 적용 시 값의 변경에 따라 행이나 열의 합이 원본의 행이나 열의 합과 일치하지 않는 단점을 해결하기 위해 원본과 결과가 동일하도록 라운딩을 적용하는 기법
아직 컴퓨터 프로그램으로 구현하기 어려워 실무에서는 잘 사용하지 않음
4. 상하단코딩
정규분포에서 적은 수의 분포를 가진 양 끝단의 정보를 범주화 등의 기법을 적용해 식별성을 낮춤
5. 로컬 일반화
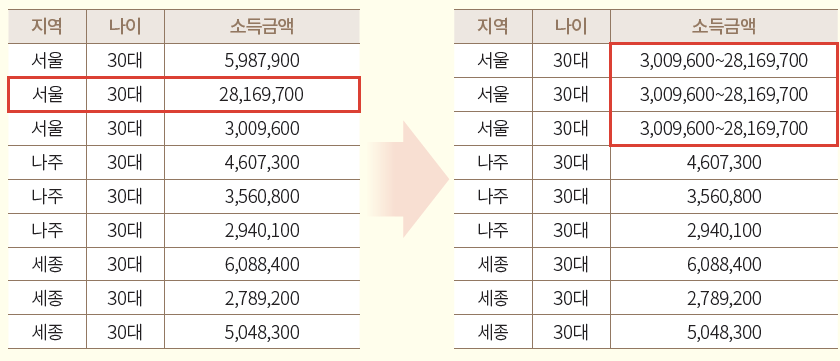
전체 정보 집합물 중 특정 열 항목에서 특이한 값을 갖거나 분포상 특이성으로 인해 식별성이 높아지는 경우 해당 부분만 일반화를 적용해 식별성을 낮추는 기법
6. 범위 방법
수치 데이터를 임의의 수 기준의 범위로 설정하는 기법으로, 해당 값의 범위 또는 구간으로 표현
ex) 소득 3300만원 -> 소득 3000~4000만원
7. 문자데이터 범주화 문자형

문자로 저장된 정보에 대해 상위의 개념으로 범주화하는 기법
암호화 수치형, 문자형데이터
1. 양방향 암호화
특정 정보에 대해 암호화와 암호화된 정보에 대한 복화가 가능한 암호화 기법
2. 일방향 암호화
원문에 대한 암호화의 적용만 가능하고 암호문에 대한 복호화 적용이 불가능한 암호화 기법
- 키가 없는 해시함수
- 키가 있는 해시함수
- 솔트가 있는 해시함수
3. 순서보존 암호화
원본 정보의 순서와 암호값의 순서가 동일하게 유지되는 암호화 방식
암호화된 상태에서도 원본 정보의 순서가 유지되어 값들 간의 크기에 대한 비교분석이 필요한 경우 안전한 분석 가능
4. 형태보존 암호화
원본 정보의 형태와 암호화된 암호값의 형태가 동일하게 유지되는 암호화방식
5. 동형암호화
암호화된 상태에서의 연산이 가능한 암호화 방식
6. 다형성 암호화
가명정보의 부정한 결합을 차단하기 위해 각 도메인별로 서로 다른 가명처리 방법을 사용하여 정보를 제공하는 방법
무작위화기술 수치형, 문자형데이터
1. 잡음 추가

개인정보에 임의의 숫자 등 잡음을 추가하는 방법
원 자료의 유효성을 해치지 않으나, 잡음값은 데이터 값과 무관하기에 유효한 데이터로 활용하기는 어려움
2. 순열
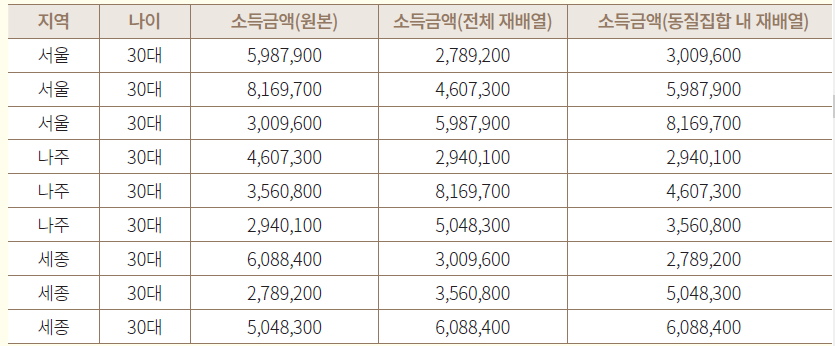
기존값은 유지하면서 식별되지 않도록 데이터 재배열
데이터 훼손 정도가 매우 큰 기법이라 조건 선정에 주의가 필요하다.
3. 토큰화

개인을 식별할 수 있는 정보를 토큰으로 변환 후 대체함으로써 개인정보를 직접 사용하여 발생하는 개인에 대한 식별 위험을 제거하여 개인정보를 보호하는 기술
의사난수생성기법, 일방향 암호화, 순서보존 암호화 기법 주로 사용
4. 난수생성기
주어진 입력 값에 대해 예측이 불가능하고 패턴이 없는 값을 생성하는 메커니즘으로 임의의 숫자를 개인정보에 할당
기타기술 수치형, 문자형데이터
1. 표본추출
데이터 주체별로 전체 모집단이 아닌 표본에 무작위 레코드 추출 등의 기법을 통해 모집단의 일부를 분석해 전체에 대한 분석을 대신하는 기법
2. 해부화
기존 하나의 데이터셋을 식별성이 있는 정보집합물과 식별성이 없는 정보집합물로 구성된 2개의 데이터셋으로 분리하는 기술
3. 재현데이터
원본과 최대한 유사한 통계적 성질을 보이는 가상의 데이터를 생성하기 위해 개인정보의 특성을 분석하여 새로운 데이터를 생성하는 기법
4. 동형비밀분산
식별정보 또는 기타 식별 가능정보를 메시지 공유 알고리즘에 의해 생성된 두 개 이상의 쉐어로 대체
5. 차분 프라이버시
특정 개인에 대한 사전지식이 있는 상태에서 해당정보가 포함된 데이터베이스와 포함되지 않은 데이터베이스 질의에 대한 응답값으로 개인을 알 수 없도록 응답 값에 임의의 숫자 잡음을 추가하여 특정 개인의 존재 여부를 알 수 없도록 하는 기법
해당 포스트는 가명처리 프로젝트 사전지식을 위해 가명정보 처리 가이드라인을 읽으며 개인적으로 요약한 포스팅입니다.
+ 프로젝트에서는 부분삭제와 마스킹 기법 이용!


